Оптическое распознавание текста в PDF документах
Оптическое распознавание текста позволяет преобразовывать изображения текста PDF документа в редактируемый текстовый формат, который поддерживает возможность поиска текста в документе, его копирование и редактирование. Распознавание текста будет осуществляться только в том случае, если в PDF документе не установлен запрет на редактирование.
Оптическое распознавание текста в Master PDF Editor основано на нейросетевых моделях Tesseract, что позволяет более точно определять символы на отсканированных документах.
Для включения оптического распознавания текста выберите в главном меню Документ > Распознавание текста. В диалоговом окне укажите следующие параметры:
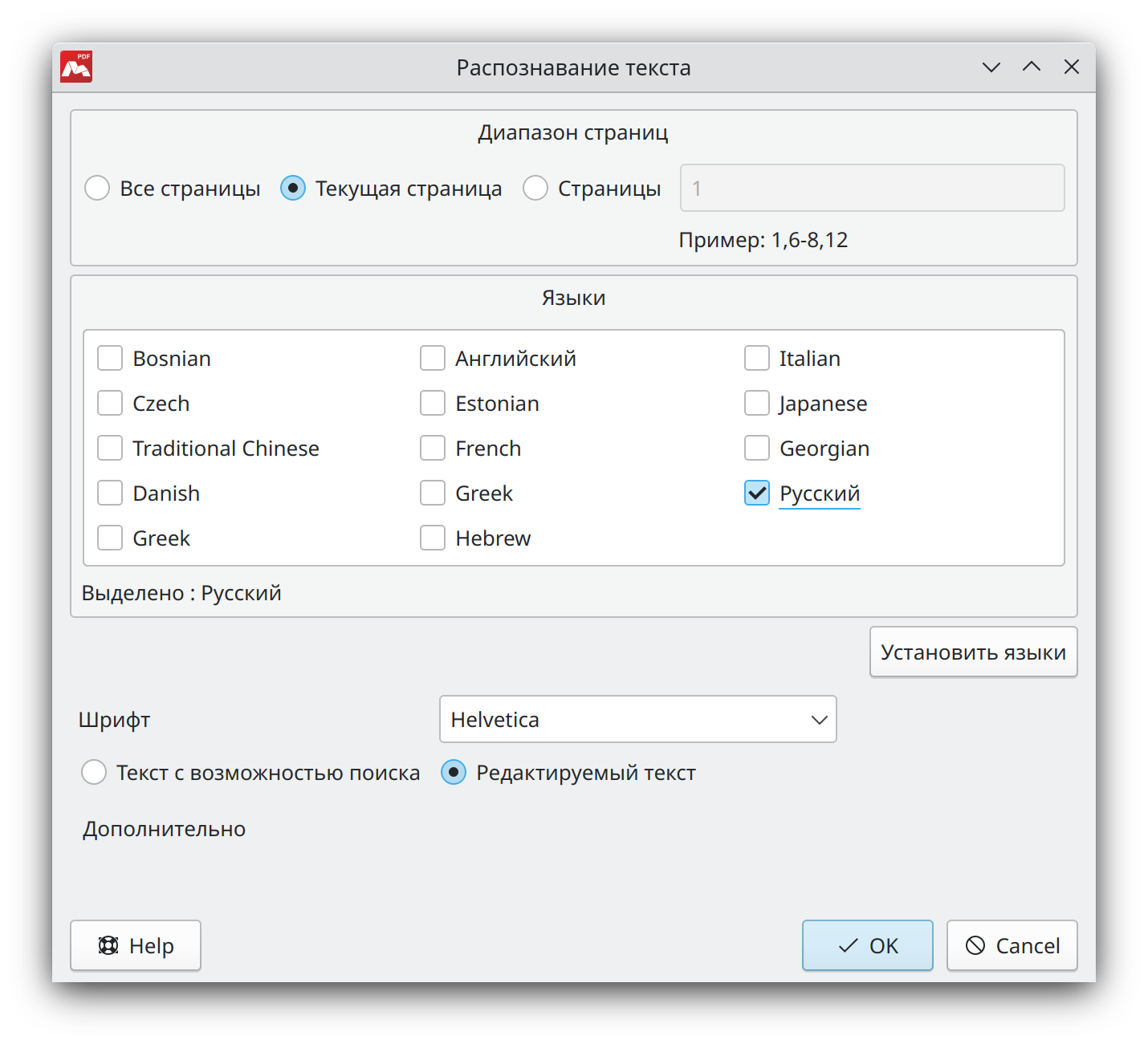
- Диапазон страниц — укажите диапазон страниц, на которых необходимо произвести распознавание текста.
- Языки — укажите язык/языки распознаваемого текста. Желательно выбирать минимальное количество вариантов. Это ускорит распознавание текста.
![]() Если распознавание текста используется первый раз, данный список будет пустым. Для добавления языков нажмите кнопку Установить языки.
Если распознавание текста используется первый раз, данный список будет пустым. Для добавления языков нажмите кнопку Установить языки.
- Установить языки — установите маркеры, чтобы выбрать необходимые варианты. В диалоговом окне перечислены языки, для которых поддерживается распознавание текста в Master PDF Editor.
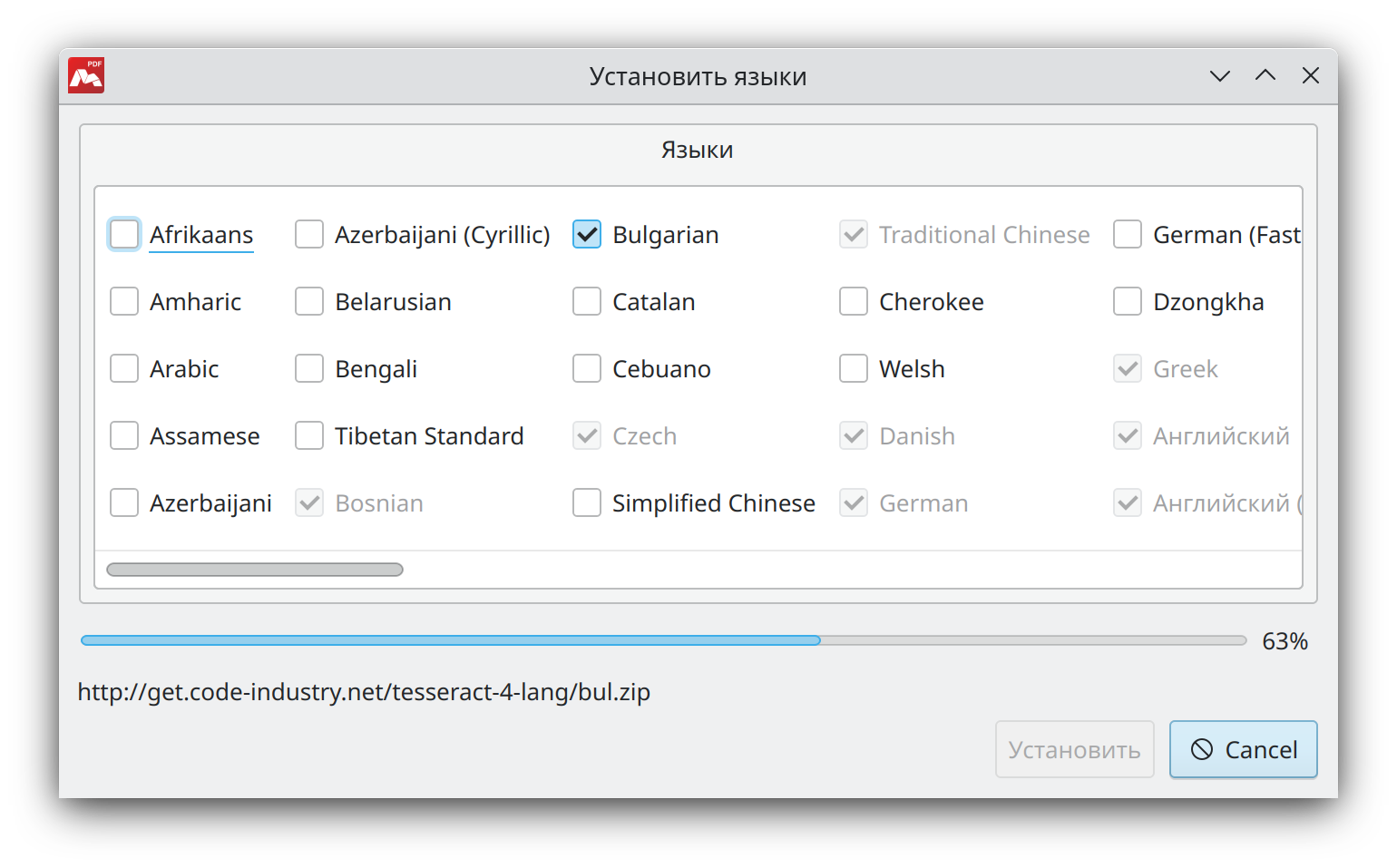
![]() Вы также можете установить дополнительные языки, которые не указаны в списке. Для этого необходимо поместить .traineddata файл в каталог, указанный в параметрах Распознавание текста в пункте Путь по умолчанию к файлам данных tesseract ocr. Путь к каталогу по умолчанию может быть изменён на другой. Если у пользователя нет права на запись для каталога, указанного в данном пути, но в нём содержатся языковые файлы, их можно использовать для распознавания текста, но установить в окне Распознавание текста не получится.
Вы также можете установить дополнительные языки, которые не указаны в списке. Для этого необходимо поместить .traineddata файл в каталог, указанный в параметрах Распознавание текста в пункте Путь по умолчанию к файлам данных tesseract ocr. Путь к каталогу по умолчанию может быть изменён на другой. Если у пользователя нет права на запись для каталога, указанного в данном пути, но в нём содержатся языковые файлы, их можно использовать для распознавания текста, но установить в окне Распознавание текста не получится.
- Шрифт — выберите вариант шрифта, который будет использоваться при форматировании уже распознанного текста. Данный параметр позволяет обеспечивать соответствие шрифтов в исходном и распознанном документах. По умолчанию выбран шрифт Helvetica.
- Текст с возможностью поиска — при выборе данной опции после завершения процедуры распознавания текст будет доступен для поиска и копирования. Распознанный текст будет вставлен в документ как невидимый под своим изображением.
- Редактируемый текст — при выборе данной опции после завершения процедуры распознавания текст будет доступен для редактирования. Распознанный текст вставится поверх изображения с данным текстом. Само изображение при этом затирается фоном.
В нижней части окна Распознавание текста находятся дополнительные настройки:
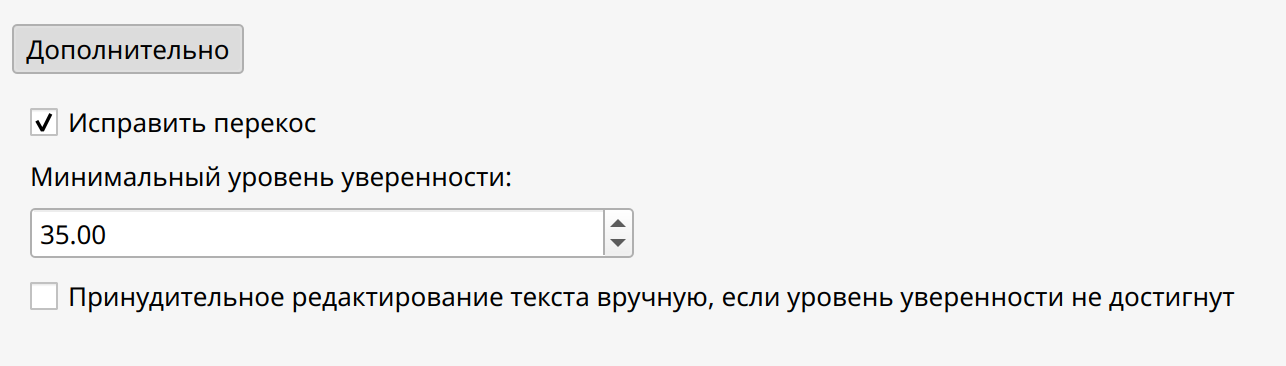
- Исправить перекос — при выборе данной опции автоматически выпрямляется и выравнивается содержимое документа. Исправить перекос можно также в содержимом отсканированного документа.
![]() Опция Исправить перекос применима только к страницам, содержащим изображения текста.
Опция Исправить перекос применима только к страницам, содержащим изображения текста.
- Минимальный уровень уверенности — числовое значение, указывающее степень уверенности механизма в том, что он правильно распознал компонент.
- Принудительное редактирование текста вручную, если уровень уверенности не достигнут — при выборе данной опции во время процедуры распознавания текста открывается диалоговое окно, в котором будет отображаться:
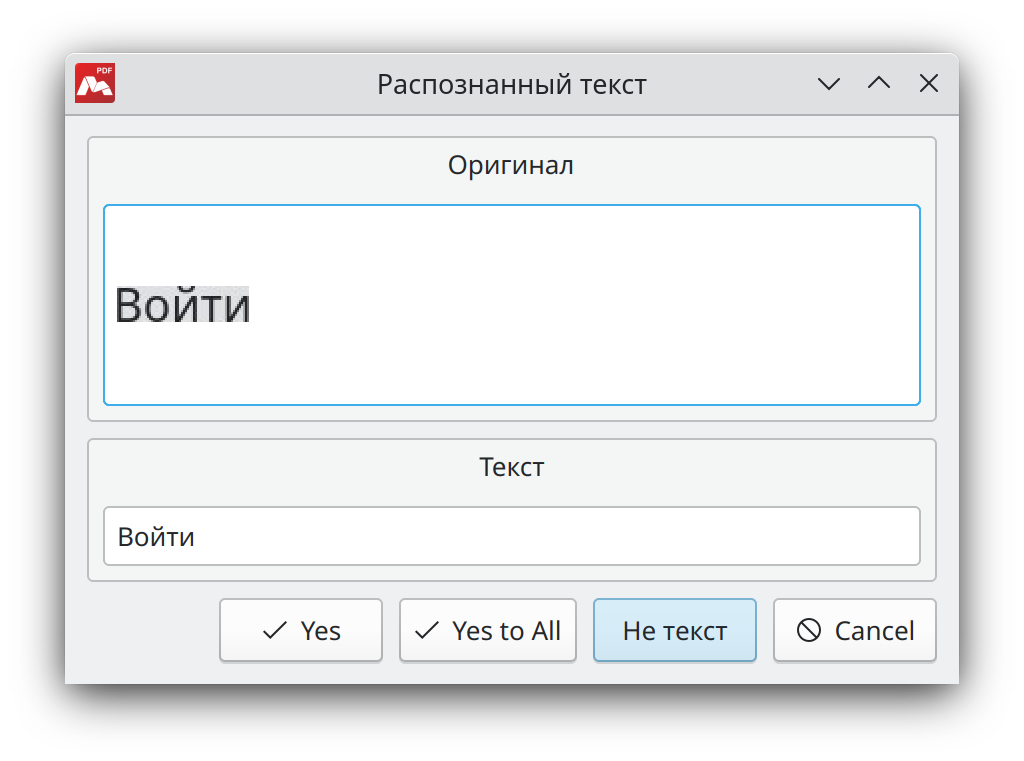
- Оригинал — фрагмент изображения с текстом
- Текст — соответствующий изображению автоматически распознанный текст.
В диалоговом окне поочередно будет отображаться каждый фрагмент изображения PDF документа с соответствующим ему распознанным текстом. Здесь можно редактировать распознанный текст перед вставкой в документ.
- Да — автоматически распознанный/редактированный текст запишется в документ. В диалоговом окне отобразится следующее изображение и текст к нему.
- Да для всех — все изображения будут распознаны автоматически и записаны в документ. Данное диалоговое окно больше не появится
- Не текст — текущий распознанный текст не является текстовым фрагментом. Отменяет вставку текста в текущем фрагменте.
- Отмена — отменить распознавание текста.
Автоматическое распознавания текста
Автоматическое распознавание выполняется последовательно при перемещении по страницам документа.
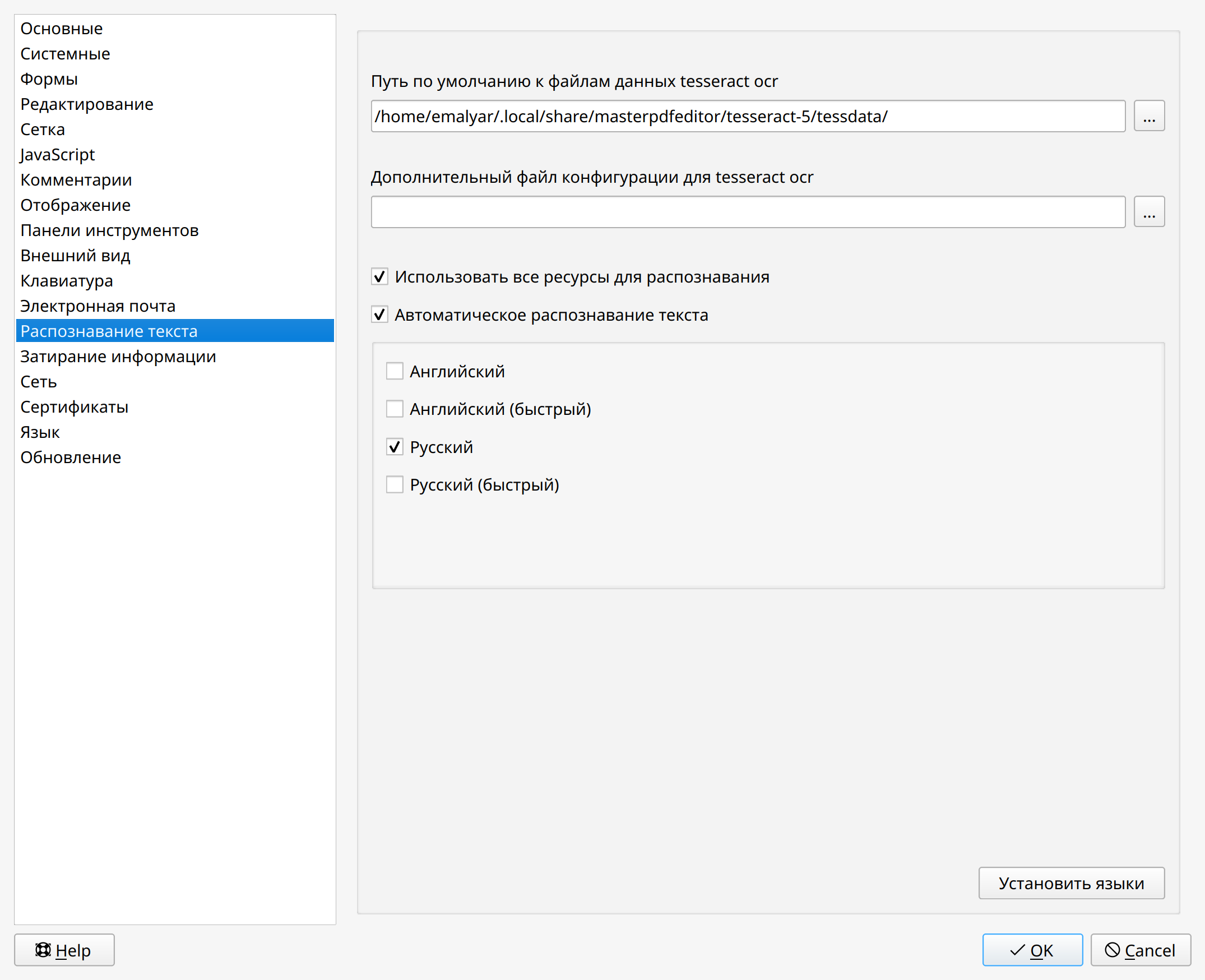
Чтобы включить автоматическое распознавание текста, поставьте галочку напротив Автоматическое распознавание текста в настройках программы. Для этого перейдите через главное меню Настройки > Параметры, откройте вкладку Распознавание текста.
Режим автоматического распознавания текста активируется, если выбран инструмент Редактирование документа или Рука.
![]() После окончания распознавания текст будет доступен для поиска и копирования.
После окончания распознавания текст будет доступен для поиска и копирования.
Перед началом распознавания убедитесь, что язык для распознавания установлен и выбран корректно. Для этого перейдите через главное меню Настройки > Параметры, откройте вкладку Распознавание текста. Под функцией Автоматическое распознавание текста выберите язык, который будет использован при автоматическом распознавании.
![]() При необходимости установите язык во вкладке Распознавание текста.
При необходимости установите язык во вкладке Распознавание текста.
![]() При автоматическом распознавании обрабатываются только страницы с изображениями и векторной графикой.
При автоматическом распознавании обрабатываются только страницы с изображениями и векторной графикой.